voidquickSort(int q[], int l, int r){ if (l >= r) return; int i = l - 1, j = r + 1, x = q[l + r >> 1]; while (i < j) { do i ++ ; while (q[i] < x); do j -- ; while (q[j] > x); if (i < j) swap(q[i], q[j]); } quickSort(q, l, j), quickSort(q, j + 1, r); }
归并排序
1 2 3 4 5 6 7 8 9 10 11 12 13
voidmergeSort(int q[], int l, int r){ if (l >= r) return; int mid = l + r >> 1; mergeSort(q, l, mid); mergeSort(q, mid + 1, r); int k = 0, i = l, j = mid + 1; while (i <= mid && j <= r) if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ]; else tmp[k ++ ] = q[j ++ ]; while (i <= mid) tmp[k ++ ] = q[i ++ ]; while (j <= r) tmp[k ++ ] = q[j ++ ]; for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j]; }
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用: intbSearch_1(int l, int r){ while (l < r) { int mid = l + r >> 1; if (check(mid)) r = mid; // check()判断mid是否满足性质 else l = mid + 1; } return l; } // 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用: intbSearch_2(int l, int r){ while (l < r) { int mid = l + r + 1 >> 1; if (check(mid)) l = mid; else r = mid - 1; } return l; }
浮点数二分
1 2 3 4 5 6 7 8 9 10 11
boolcheck(double x){/* ... */} // 检查x是否满足某种性质
doublebSearch_3(double l, double r){ constdouble eps = 1e-6; // eps 表示精度,取决于题目对精度的要求 while (r - l > eps) { double mid = (l + r) / 2; if (check(mid)) r = mid; else l = mid; } return l; }
高精度
高精度加法
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// C = A + B, A >= 0, B >= 0 vector<int> add(vector<int> &A, vector<int> &B){ if (A.size() < B.size()) returnadd(B, A); vector<int> C; int t = 0; for (int i = 0; i < A.size(); i ++ ) { t += A[i]; if (i < B.size()) t += B[i]; C.push_back(t % 10); t /= 10; } if (t) C.push_back(t); return C; }
高精度减法
1 2 3 4 5 6 7 8 9 10 11 12 13
// C = A - B, 满足A >= B, A >= 0, B >= 0 vector<int> sub(vector<int> &A, vector<int> &B){ vector<int> C; for (int i = 0, t = 0; i < A.size(); i ++ ) { t = A[i] - t; if (i < B.size()) t -= B[i]; C.push_back((t + 10) % 10); if (t < 0) t = 1; else t = 0; } while (C.size() > 1 && C.back() == 0) C.pop_back(); return C; }
高精度乘低精度
1 2 3 4 5 6 7 8 9 10 11 12
// C = A * b, A >= 0, b >= 0 vector<int> mul(vector<int> &A, int b){ vector<int> C; int t = 0; for (int i = 0; i < A.size() || t; i ++ ) { if (i < A.size()) t += A[i] * b; C.push_back(t % 10); t /= 10; } while (C.size() > 1 && C.back() == 0) C.pop_back(); return C; }
高精度除以低精度
1 2 3 4 5 6 7 8 9 10 11 12 13
// A / b = C ... r, A >= 0, b > 0 vector<int> div(vector<int> &A, int b, int &r){ vector<int> C; r = 0; for (int i = A.size() - 1; i >= 0; i -- ) { r = r * 10 + A[i]; C.push_back(r / b); r %= b; } reverse(C.begin(), C.end()); while (C.size() > 1 && C.back() == 0) C.pop_back(); return C; }
//二分求出x对应的离散化的值 intfind(int x){ int l = 0, r = alls.size() - 1; while(l < r) { int mid = l + r >> 1; if(alls[mid] >= x) r = mid; else l = mid + 1; } return r + 1; }
尺取法(双指针)
1 2 3 4 5 6 7
for (int i = 0, j = 0; i < n; i ++ ) { while (j < i && check(i, j)) j ++ ; // 具体问题的逻辑 } //常见问题分类: //(1) 对于一个序列,用两个指针维护一段区间 //(2) 对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作
数论与数学知识
c++求上取整
⌈lp⌉=⌊l+p−1p⌋
快速幂
1 2 3 4 5 6 7 8 9
intqpow(int a, int b, int c){ int res = 1; while(b){ if(b & 1) res = res * a % c; //不可写成res *= a % c b >>= 1; a = a * a % c; } return res; }
逆元
费马小定理求逆元
费马小定理(Fermat’s little theorem)是数论中的一个重要定理,在1636年提出。如果p是一个质数,而整数a不是p的倍数,则有
ap−1≡1(mod p)
对上式变形得
ap−2a≡1(mod p)
则a mod p的逆元是ap−2
接下来通过qpow(a, p - 2, p)即可求出a mod p的逆元
快速幂求逆元
基于费马小定理,求a mod p的逆元。
要求是p是一个质数,并且p与a互质。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
intqPow(int a, int b, int k){ int ans = 1; while (b) { if (b & 1) ans = (LL)ans * a % k; a = (LL)a * a % k; b >>= 1; } return ans; }
{ int res = q_pow(a, p - 2, p); if (a % p) printf("%d\n", res); elseputs("impossible"); }
for (int i = 2; i <= n; i ++) { s[i] = s[i - 1] * a[i] % p; }
inv[n] = qpow(s[n],p - 2);
for (int i = n - 1; i >= 1; i --) { inv[i] = inv[i + 1] * a[i + 1] % p; }
for (int i = 2; i <= n; i ++) { inv[i] = inv[i] * s[i - 1] % p; }
扩展欧几里得算法
1 2 3 4 5 6 7 8 9 10 11 12 13
intexgcd(int a, int b, int &x, int &y)// 扩展欧几里得算法, 求x, y,使得ax + by = gcd(a, b) { if (!b) { x = 1; y = 0; return a; } //d始终都是a和b的最大公约数, 倒着传参是为了简化计算 int d = exgcd(b, a % b, y, x); y -= (a / b) * x; return d; //返回d,使得能够在求最大公约数的同时完成x,y的凑整 }
intgauss(){ int c, r; for (r = 1, c = 1; c <= n; c ++) { int t = r; for (int i = r + 1; i <= n; i ++) if (fabs(a[i][c]) - fabs(a[t][c]) > eps) t = i; if (fabs(a[t][c]) < eps) continue; if (t != r) swap(a[t], a[r]); for (int i = n + 1; i >= c; i --) a[r][i] /= a[r][c]; for (int i = r + 1; i <= n; i ++) { if (fabs(a[i][c]) > eps) for (int j = n + 1; j >= c; j --) a[i][j] -= a[r][j] * a[i][c]; } r ++; } if (r <= n) { for (int i = r; i <= n; i ++) { if (fabs(a[i][n + 1]) > eps) return2; // 代表有无穷多组解 } return1; // 代表无解 } for (int i = n; i >= 1; i --) { for (int j = i + 1; j <= n; j ++) { a[i][n + 1] -= a[i][j] * a[j][n + 1]; } } // 代表有唯一组解 return0; }
筛质数
朴素筛法
1 2 3 4 5 6 7 8
voidgetPrimes(int n){ for (int i = 2; i <= n; i ++) { if (!st[i]) { primes[cnt ++] = n; } for (int j = i + i; i <= n; j += i) st[j] = true; } }
inteuler(int a){ int res = a; for (int i = 2; i <= a / i; i ++) { if (a % i == 0) { res = res / i * (i - 1); while (a % i == 0) a /= i; } } if (a > 1) res = res / a * (a - 1); return res; }
intkruskal(){ sort(edges, edges + m); // 将边按照权重从小到大排序 for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集 int res = 0, cnt = 0; for (int i = 0; i < m; i ++ ) { int a = edges[i].a, b = edges[i].b, w = edges[i].w; a = find(a), b = find(b); // 判断两个节点是否在同一个连通块中 if (a != b) { p[a] = b; // 将两个连通块合并 res += w; // 将边权重累加到结果中 cnt ++ ; // 记录加入生成树的边的数量 } } if (cnt < n - 1) return INF; // 判断生成树中是否包含n-1条边 return res; }
{ for (int i = 0; i < m; i ++ ) { int a, b, w; scanf("%d%d%d", &a, &b, &w); edges[i] = {a, b, w}; } int t = kruskal(); if (t == INF) puts("impossible"); // 无法生成最小生成树 elseprintf("%d\n", t); // 输出最小生成树的权重 }
// depth表示某个节点在树中的深度,其中根节点的dpeth为1, 越往下深度越大。 // fa[i][k]指节点i向上走2^k布所能到达的节点。 // fa的第二个参数,是向上走的最大距离取log下取整,这里是对点数4e4取log得15 int depth[N], fa[N][16];
// 通过宽搜来初始化depth和fa数组。 voidbfs(int root){ queue<int> q; memset(depth, 0x3f, sizeof depth); // 这里depth[0] = 0起哨兵作用,以防跳出根节点之上。 depth[0] = 0, depth[root] = 1; q.push(root); while (!q.empty()) { int t = q.front(); q.pop(); for (int i = h[t]; ~i; i = ne[i]) { int j = e[i]; if (depth[j] > depth[t] + 1) { depth[j] = depth[t] + 1; q.push(j); fa[j][0] = t; for (int k = 1; k <= 15; k ++) { fa[j][k] = fa[fa[j][k - 1]][k - 1]; } } } } }
intlca(int a, int b){ if (depth[a] < depth[b]) swap(a, b); for (int k = 15; k >= 0; k --) { if (depth[fa[a][k]] >= depth[b]) { a = fa[a][k]; } // 使a尽量跳到和b同层,并最终一定能跳到。 } if (a == b) return a; for (int k = 15; k >= 0; k --) { if (fa[a][k] != fa[b][k]) { a = fa[a][k]; b = fa[b][k]; } } return fa[a][0]; }
dfs版本预处理
同时顺便求出每个节点向上对应步数的最小的边权
1 2 3 4 5 6 7 8 9 10 11 12 13 14
voiddfs(int u, int fa){ depth[u] = depth[fa] + 1; f[u][0] = fa; for (int i = 1; 1 << i < depth[u]; i ++) { f[u][i] = f[f[u][i - 1]][i - 1]; minv[u][i] = min(minv[f[u][i - 1]][i - 1], minv[u][i - 1]); } for (int i = h[u]; ~i; i = ne[i]) { int j = e[i]; if (j == fa) continue; minv[j][0] = w[i]; dfs(j, u); } }
voideval(){ auto b = num.top(); num.pop(); auto a = num.top(); num.pop(); auto c = op.top(); op.pop(); int x; if(c == '+') x = a + b; elseif (c == '-') x = a - b; elseif (c == '*') x = a * b; else x = a / b; num.push(x); }
{ unordered_map<char, int> pr{{'+', 1}, {'-', 1}, {'*', 2}, {'/', 2}}; string str; cin >> str; for (int i = 0; i < str.size(); i ++) { auto c = str[i]; if (isdigit(c)) { int x = 0, j = i; while (j < str.size() && isdigit(str[j])) x = x * 10 + str[j ++] - '0'; i = j - 1; num.push(x); } elseif (c == '(') op.push(c); elseif (c == ')') { while (op.top() != '(') eval(); op.pop(); } else { while (op.size() && pr[op.top()] >= pr[c]) eval(); op.push(c); } } while (op.size()) eval(); cout << num.top() << endl; }
单调栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14
int stk[N], tt; int n; int a[N];
{ cin >> n; for (int i = 1; i <= n; i ++) scanf("%d", &a[i]); for (int i = 1; i <= n; i ++) { while (tt && stk[tt] >= a[i]) tt --; if (tt) cout << stk[tt] << ' '; else cout << -1 << ' '; stk[++ tt] = a[i]; } }
voidinsert(char str[]){ int p = 0; // 每次从根节点开始找 for (int i = 0; str[i]; i ++) { int u = str[i] - 'a'; if (!son[p][u]) son[p][u] = ++idx; p = son[p][u]; } cnt[p] ++; //标记不是打在要插入的字符串的最后一个字母对应的节点的下一个节点上的*** }
intquery(char str[]){ int p = 0; for (int i = 0; str[i]; i ++) { int u = str[i] - 'a'; if (!son[p][u]) return0; p = son[p][u]; } return cnt[p]; }
voidbuild(int u, int l, int r){ if (l == r) tr[u] = {l, r, w[r]}; else { tr[u] = {l, r}; int mid = l + r >> 1; build(u << 1, l, mid), build(u << 1 | 1, mid + 1, r); pushup(u); } }
intquery(int u, int l, int r){ if (tr[u].l >= l && tr[u].r <= r) return tr[u].sum; int mid = tr[u].l + tr[u].r >> 1; int sum = 0; if (l <= mid) sum = query(u << 1, l, r); if (r > mid) sum += query(u << 1 | 1, l, r); return sum; }
voidmodify(int u, int x, int v){ if (tr[u].l == tr[u].r) tr[u].sum += v; else{ int mid = tr[u].l + tr[u].r >> 1; if (x <= mid) modify(u << 1, x, v); elsemodify(u << 1 | 1, x, v); pushup(u); } }
voiddfs0(int u, int fa){ sz[u] = 1; for (int i = h[u]; ~i; i = ne[i]) { int j = e[i]; if (j == fa) continue; dfs0(j, u); sz[u] += sz[j]; if (sz[j] > sz[son[u]]) son[u] = j; } }
// pson代表当前u的重儿子,即不要重复算重儿子的部分 voidupdate(int u, int fa, int sign, int pson){ cnt[c[u]] += sign; if (cnt[c[u]] > mx) mx = cnt[c[u]], sum = c[u]; elseif (cnt[c[u]] == mx) sum += c[u]; for (int i = h[u]; ~i; i = ne[i]) { int j = e[i]; if (j == fa || j == pson) continue; update(j, u, sign, pson); } }
// op代表u是重儿子还是轻儿子 voiddfs(int u, int fa, int op){ for (int i = h[u]; ~i; i = ne[i]) { int j = e[i]; if (j == fa || j == son[u]) continue; dfs(j, u, 0); } if (son[u]) dfs(son[u], u, 1); update(u, fa, 1, son[u]); ans[u] = sum; if (!op) update(u, fa, -1, 0), sum = mx = 0; }
// 代码为统计一段区间上是否有不相同的数,没有输出yes int n, q; int a[N]; vector<array<int, 3>> v; int cnt[210]; int ans[N]; int len;
intget(int x){ return x / len; }
voidadds(int x, int &res){ if (!cnt[x]) res ++; cnt[x] ++; }
voiddel(int x, int &res){ cnt[x] --; if (!cnt[x]) res --; }
voidsolve(){ cin >> n >> q; len = max(1, (int)sqrt((double)n * n / q)); for (int i = 1; i <= n; i ++) { cin >> a[i]; a[i] += 100; } for (int i = 1; i <= q; i ++) { int l, r; cin >> l >> r; v.push_back({i, l, r}); } auto cmp = [&](array<int, 3> &a, array<int, 3> &b) { int i = get(a[1]), j = get(b[1]); if (i != j) return i < j; return a[2] < b[2]; }; sort(v.begin(), v.end(), cmp); // i是右指针,j是左指针 for (int k = 0, i = 0, j = 1, res = 0; k < q; k ++) { int id = v[k][0], l = v[k][1], r = v[k][2]; while (i < r) adds(a[++ i], res); while (i > r) del(a[i --], res); while (j < l) del(a[j ++], res); while (j > l) adds(a[-- j], res); ans[id] = res; } for (int i = 1; i <= q; i ++) if (ans[i] == 1) cout << "YES\n"; else cout << "NO\n"; }
structNode { int lson, rson; int cnt; }tr[N * 17 * 18]; int root[N]; int c[N]; int idx;
intinsert(int p, int l, int r, int x){ int q = ++idx; tr[q] = tr[p]; if (l == r) { tr[q].cnt ++; return q; } int mid = l + r >> 1; if (x <= mid) tr[q].lson = insert(tr[p].lson, l, mid, x); else tr[q].rson = insert(tr[p].rson, mid + 1, r, x); tr[q].cnt = tr[tr[q].lson].cnt + tr[tr[q].rson].cnt; return q; }
intquery(int q, int p, int l, int r, int k){ if (l == r) return l; int cnt = tr[tr[q].lson].cnt - tr[tr[p].lson].cnt; int mid = l + r >> 1; if (k <= cnt) returnquery(tr[q].lson, tr[p].lson, l, mid, k); elsereturnquery(tr[q].rson, tr[p].rson, mid + 1, r, k - cnt); }
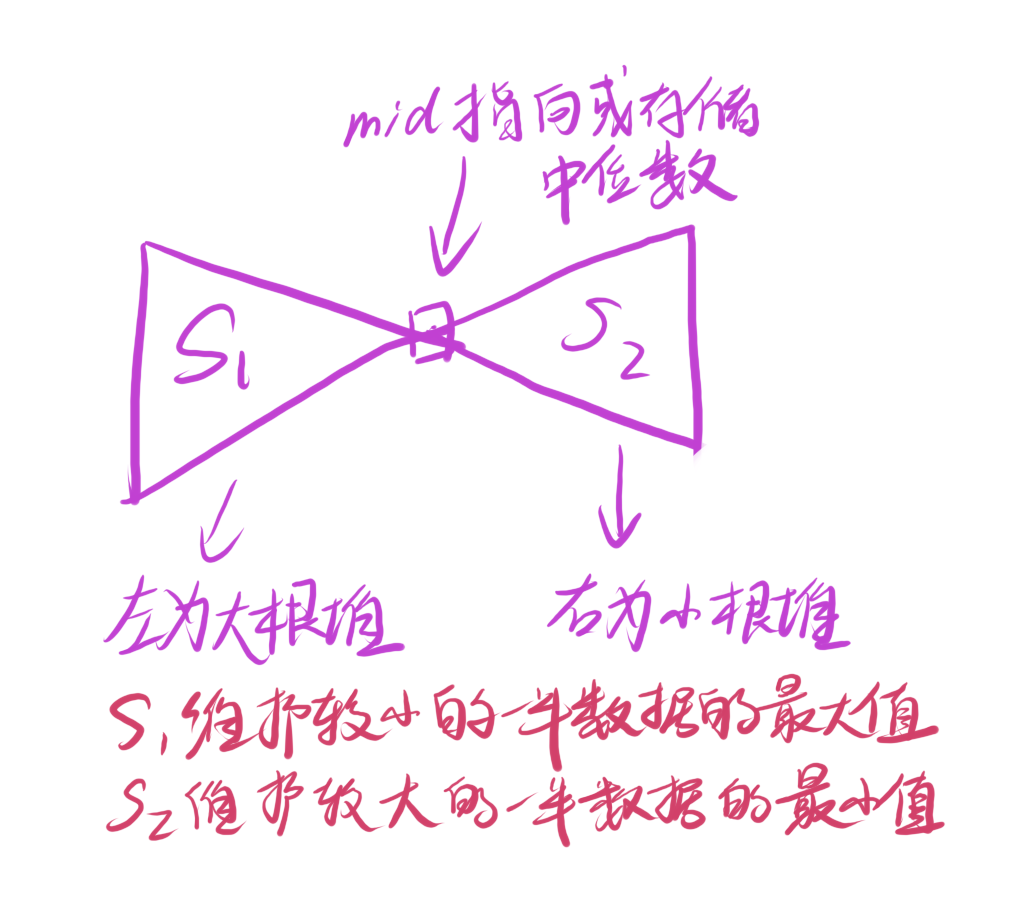
查询中位数的时候直接取个数较多的堆的堆顶即可。
动态规划
最长上升子序列
1.朴素版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
int n; int a[N]; int dp[N]; //dp中存的是以a[i]结尾的子序列的集合中最长的子序列的长度
{ for(int i = 1; i <= n; i ++){ dp[i] = 1; for(int j = 1; j < i; j ++){ if(a[j] < a[i]){ dp[i] = max(dp[i], dp[j] + 1); } } } int ans = 0; for(int j = 1; j <= n; j ++) ans = max(ans, dp[j]); cout << ans; }
2.1模拟栈版本
1 2 3 4 5 6 7 8 9 10 11 12
{ vector<int> arr(n); vector<int> stk;//模拟堆栈 stk.push_back(arr[0]); for (int i = 1; i < n; ++i) { if (arr[i] > stk.back()) //如果该元素大于栈顶元素,将该元素入栈 stk.push_back(arr[i]); else//替换掉第一个大于或者等于这个数字的那个数 *lower_bound(stk.begin(), stk.end(), arr[i]) = arr[i]; } cout << stk.size() << endl; }
2.2二分写法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
int n; int a[N]; int q[N];
{ int len = 0; for (int i = 0; i < n; i ++) { int l = 0, r = len; while (l < r) { int mid = l + r + 1 >> 1; if (q[mid] < a[i]) l = mid; else r = mid - 1; } len = max(len, r + 1); q[r + 1] = a[i]; } printf("%d\n", len); }
voidsubseq1(int a[], int l, int r){ // 对原数组的每个下标i(从1开始),求以a[i]结尾的最长不下降子序列长度 int len = 0; // q下标从2开始才放如元素,q[i]是有长度为i-1的子序列的最小的末尾值 for (int i = l; i <= r; i ++) { int ll = l, rr = len + 1; while (ll < rr) { int mid = ll + rr + 1 >> 1; if(q[mid] <= a[i]) ll = mid; else rr = mid - 1; } len = max(len, rr); q[rr + 1] = a[i]; } // 二分求出以a[i]结尾的最长不下降子序列长度 for (int i = l; i <= r; i ++) { int l2 = 2, r2 = len + 1; while (l2 < r2) { int mid = l2 + r2 + 1 >> 1; if(q[mid] <= a[i]) l2 = mid; else r2 = mid - 1; } dp1[i] = l2 - 1; } }
背包问题
01背包
状态表示:f[i][j]:在前i个物品中选,总体积不超过j的最大价值。
01背包问题的二维代码
1 2 3 4 5 6 7 8 9 10 11
{ //动态规划问题一般下标从1开始,便于从0的情况递推结果。 for (int i = 1; i <= n; i ++) { for (int j = 1; j <= m; j ++) { f[i][j] = f[i - 1][j]; if (j >= v[i]) { f[i][j] = max(f[i][j], f[i - 1][j - v[i]] + w[i]); } } } }
01背包一维优化
1 2 3 4 5 6 7
{ for (int i = 1; i <= n; i ++) { for (int j = m; j >= v[i]; j --) { f[j] = max(f[j], f[j - v[i]] + w[i]); } } }
完全背包问题
特征:一个物品可以选无数次。
状态表示:f[i][j]表示从前i个物品里选择(一个物品可以选多次),总体积不超过j的最大价值。
完全背包问题的三重循环代码
1 2 3 4 5 6 7 8 9
{ for (int i = 1; i <= n; i ++) { for (int j = 1; j <= m; j ++) { for (int k = 0; k * v[i] <= j; k ++) { f[i][j] = max(f[i][j], f[i - 1][j - k * v[i]] + k * w[i]); } } } }
//s[i]表示第i种物品共有s[i]个 int f[N][N], s[N], v[N], w[N];
{ for (int i = 1; i <= n; i ++) { for (int j = 1; j <= m; j ++) { for (int k = 0; k <= s[i] && k * v[i] <= j; k ++) { f[i][j] = max(f[i][j], f[i - 1][j - k * v[i]] + k * w[i]); } } } }
多重背包问题一维优化代码
1 2 3 4 5 6 7 8 9
{ for (int i = 1; i <= n; i ++) { for (int j = m; j >= v[i]; j --) { for (int k = 0; k <= s[i] && k * v[i] <= j; k ++) { f[j] = max(f[j], f[j - k * v[i]]+ k * w[i]); } } } }
// s[i]存储第i种物品的个数 // a, b数组存的是原体积和原价值 int a[N], b[N]; int v[N], w[N], s[N];
{ int cnt = 0; for (int i = 1; i <= n; i ++) { int k = 1; int ss = s[i]; while (k <= s) { cnt ++; v[cnt] = k * a[i]; w[cnt] = k * b[i]; s -= k; k *= 2; } if (s > 0) { cnt ++; v[cnt] = s * a; w[cnt] = s * b; } } for (int i = 1; i <= cnt; i ++) { for (int j = m; j >= v[i]; j --) { f[j] = max(f[j], f[j - v[i]] + w[i]); } } }
// w[i][j]代表第i组物品中的第j个的价值,v同 int w[N][N],v[N][N]; // s[i]代表第i组物品有多少个 int f[N],s[N];
{ for (int i = 1; i <= n; i ++) { for (int j = m; j >= 0; j --) { for (int k = 1; k <= s[i]; k ++) { if (v[i][k] <= j) { f[j] = max(f[j], f[j - v[i][k]] + w[i][k]); } } } } return0; }
背包问题中总体积最多/恰好/最少为j, 以求最大值为例(3是最小值)
体积最多为j:memset(f, 0, sizeof f), v >= 0
体积恰好为j:memset(f, -0x3f, sizeof f), ,f[0] = 0, v >= 0
voiddfs(int u){ // 相当于分组背包问题中的物品组 for (int u = h[u]; ~i; i = ne[i]) { int son = e[i]; dfs(son); // 先求一下所有子树中的最大价值, 故先在最大体积中把当前节点去掉 // 枚举体积 for (int j = m - v[u]; j >= 0; j --) { // 枚举决策,这里以选取体积为多少讨论决策 for (int k = 0; k <= j; k ++) { f[u][j] = max(f[u][j], f[u][j - k] + f[son][k]); } } } // 最后记得把当前节点加上 for (int j = m; j >= v[u]; j --) f[u][j] = f[u][j - v[u]] + w[u]; for (int j = v[u] - 1; j >= 0; j --) f[u][j] = 0; }
dfs(root);
另一种模板:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
int f[110][110];//f[x][v]表达选择以x为子树的物品,在容量不超过v时所获得的最大价值 vector<int> g[110]; int v[110], w[110]; int n, m, root;
voiddfs(int x){ for (int i = v[x]; i <= m; i ++) f[x][i] = w[x];//点x必须选,所以初始化f[x][v[x] ~ m]= w[x] for (int i = 0; i < g[x].size(); i ++) { int y = g[x][i]; dfs(y); for (int j = m; j >= v[x]; j --)//j的范围为v[x]~m, 小于v[x]无法选择以x为子树的物品 { for (int k = 0; k <= j - v[x]; k ++)//分给子树y的空间不能大于j-v[x],不然都无法选根物品x { f[x][j] = max(f[x][j], f[x][j - k] + f[y][k]); } } } }